Intro Ramble
I have been working on parsing and converting an XML document into a MySQL database, and I thought i'd share my findings in how you can parse an XML document with PHP, I have unfortunately not yet found a good method of putting it all into a MySQL database, This is what I've learned thus far.
The XML document that we will be parsing, is this blog's RSS feed, an RSS Feed is basically like a blog that updates when your blog updates, but instead of a neat blog design with headlines and nice text, we instead get mumbo jump code that looks very familiar to HTML, click the link below and you will see what I mean.
http://helgesverre.com/blog/feed
What Does Parsing Mean?
I throw around the word "Parsing" and "parse", but what does "parsing" something actually entail and what does it mean to "parse" a document?
resolve (a sentence) into its component parts and describe their syntactic roles."I asked a couple of students to parse these sentences for me"
As the quote I copied from a quick Google search says, Parsing an XML document, pretty much means that we are going to break it down into smaller components that we can work with more easily. Confused yet? read on...
In our XML document there are several tags named <item>, within this node there are various child nodes: <title> ,
<link> , <pubDate> etc. (I call everything within <tags>I AM A NODE</tags> for a node, this is probably not the
correct technical term, but it makes more sense to me).
The <channel> node represents the entire blog, the blog has several blog posts(<item> ) and each blog post have a
title, summary(<description> ), publication date( <pubDate> ) and various other information.
These <item> nodes represents my blog posts, as you can see in the picture below.
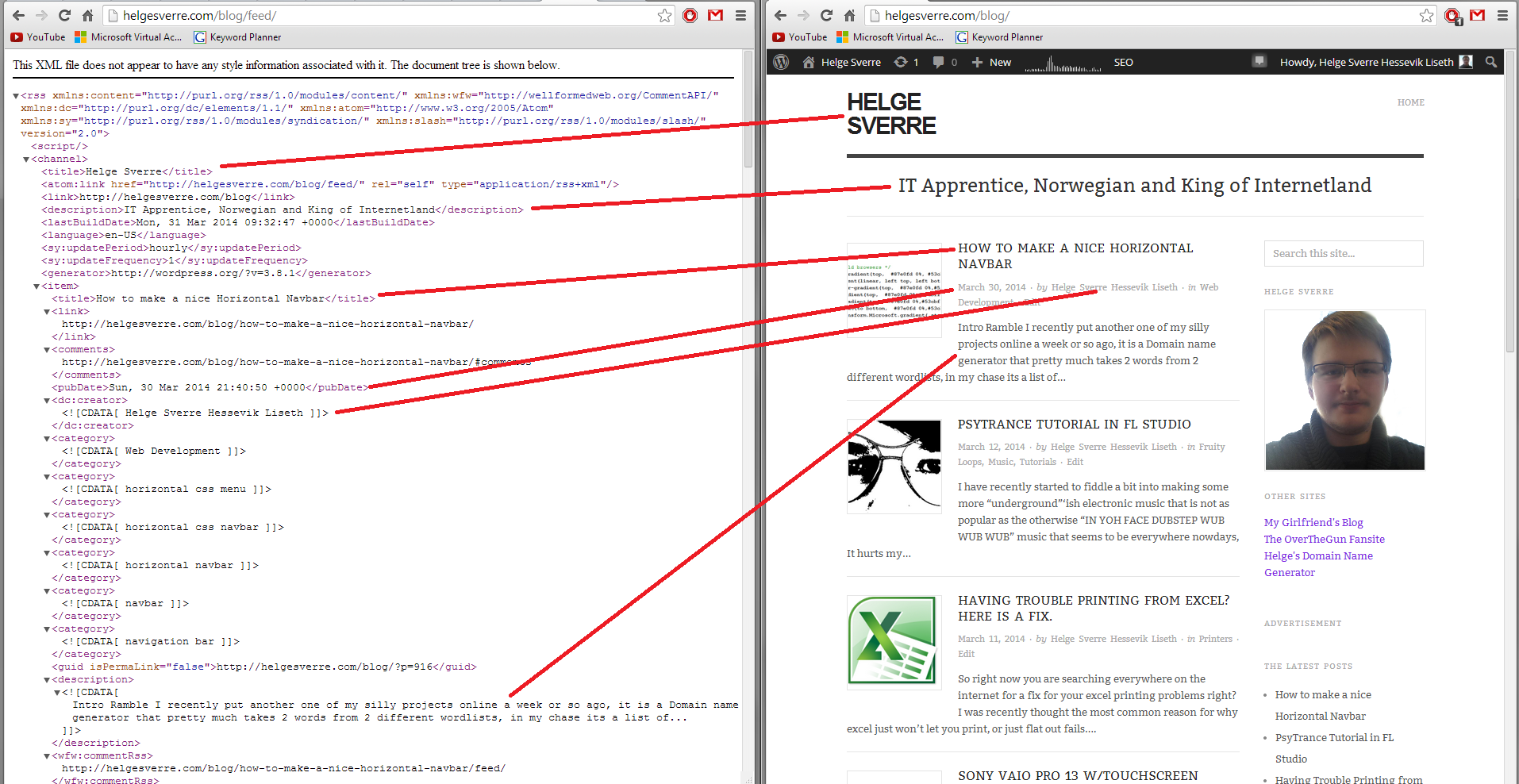
The XML represents my blog posts. (Click for larger image)
How to Parse XML in PHP
To parse our XML data in PHP we are going to use the built-in function simplexml_load_string() which takes 1 parameter (It really takes 5, but 4 of them is optional and unnecessary: more info), that one parameter is a string of XML data, so what we're gonna do is to feed it our RSS feed as a string, to do this we need to use the function file_get_contents() :
<?php
$feed = file\_get\_contents("http://helgesverre.com/blog/feed");
$xml = simplexml\_load\_string($feed);
?>
The XML data that we are going to parse has these nodes inside it(some are left out, I am simplifying.)
<channel>
<item>
<title>I am a title</title>
<link>http://example.com/i-am-a-link</link>
<pubDate>Sun, 30 Mar 2014 21:40:50 +0000</pubDate>
<dc:creator>Author Mc Swagger</dc:creator>
<description>I am a description, i am the summary of the post</description>
<guid>http://example.com/?p=123</guid>
</item>
</channel>
We have several nodes named <item> within this node there are various child nodes( <title> , <link> , <pubDate>
etc..).
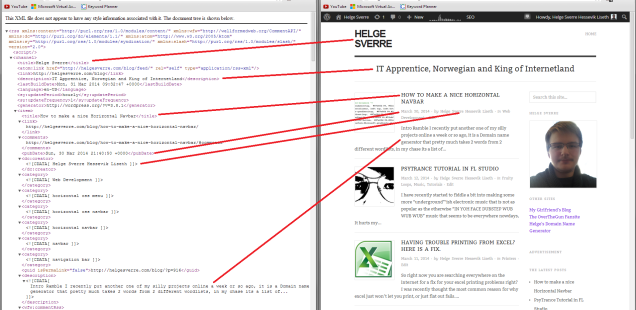
These <item> nodes represents my blog posts as you can see in the picture below.
The <channel> node represents the entire blog, the blog has several blog posts(<item> ) and each blog post have a
title, summary(<description> ), publication date(<pubDate> ) and various other information.
The XML Data Represents My Blog Posts
Why not use more meaningful node names like <blog> and <post>?
Technically there is nothing stopping us from making our RSS feed use those tagnames, the reason we use various standard tagnames is because WordPress among a lot of other blog publishing tools and CMS's enforce the RSS convention that is adviced by the RSS Advisory Board.
Although we don't need to bother with knowing these things, it's nice to know why certain things are formatted a certain way.
Moving on.
We have successfully Parsed in our XML data and now our $xml variable contains various objects that represent our XML document's nodes, we want to access these XML nodes in our PHP code.
To do this we have to specify which node we want by using $xml->NODE to traverse the "XML node three", Where NODE represents a node in our XML document.
Recall the code snippet of our XML structure above? we are accessing the <channel> node because that node is the
parent of our <item> nodes, we have to access the nodes in the order that they appear in the XML three.
<?php
$feed = file_get_contents("http://helgesverre.com/blog/feed");
$xml = simplexml_load_string($feed);
// Display the first post title
echo $xml->channel->item[0]->title;
// This will display "How to make a nice horizontal navbar" at the time of this writing.
?>
We write item[0] because our XML document have many <item> nodes within our <channel> node, and we are accessing the
first(In most programming languages, counting USUALLY starts on 0 instead of 1).
We can also grab the 2nd blog posts by writing item[1] instead, like this:
<?php
$feed = file_get_contents("http://helgesverre.com/blog/feed");
$xml = simplexml_load_string($feed);
// Display the second post title
echo $xml->channel->item[1]->title;
// This will display "PsyTrance Tutorial in FL Studio" at the time of this writing.
?>
Now, What if we wanted to get all our post titles?
We would do this with a simple for loop.
<?php
$feed = file_get_contents("http://helgesverre.com/blog/feed");
$xml = simplexml_load_string($feed);
// This will display all the posts in the RSS feed.
for ($i = 0; $i < count($xml->channel->item); $i++ ) {
echo $xml->channel->item[$i]->title . "<br> ";
}
?>
You can check out the Live Demo of the code above here.
That is pretty much all there is to it. If you have any more questions, feel free to post them in the comments :)
If you want to yell at me for using the wrong terminology, please comment below calling me a dumbass ;D
